Google Cloud Print
Google Cloud Print es un servicio de Google creado para permitir que cualquier aplicación con Cloud-Print de cualquier dispositivo en la nube pueda imprimir desde cualquier impresora, sin necesidad de instalación de ningún tipo de drivers por parte del usuario.
Google Cloud Print usa del protocolo XMPP y del puerto 5222 para realizar las comunicaciones con el servidor de impresión. Las transferencias de archivos se realizan por el puerto 443.
Los únicos requisitos que se exigen para su uso, son los de tener una cuenta de Google, un navegador Google Chrome y una impresora. Se recomienda que preferiblemente sea una impresora preparada para imprimir en la nube, ya que no necesitan de un ordenador para su configuración.
Si se trata de una impresora normal, habrá que registrarla en la cuenta de google Cloud Print, recomendando para ello tener instalado, al menos, Windows XP SP3 y un navegador Google Chrome.
Si lo que queremos es usar una impresora preparada para para imprimir en la nube, la página de Google Cloud Print nos proporciona una lista de marcas que disponen de este tipo de impresoras:
http://www.google.es/cloudprint/learn/printers.html
Accediendo a cada marca podremos ver que modelos tienen dicha característica.
Las grandes ventajas que dispone este servicio de impresión en la nube, frente a las que funcionan vía WiFi, consiste en que con Google Cloud Print se puede imprimir desde cualquier dispositivo con tu cuenta de Google, compartir tus impresoras e imprimir a través de Internet sin necesidad de usar configuración de proxys. Algo necesario si se pretende hacer algo parecido mediante impresoras WiFi.
Además, como ya he puntualizado anteriormente, no es necesario la dependencia de instalación de drivers para cada ordenador en concreto, como cuando se usan impresoras convencionales.
Instalación y Configuración
Voy a proceder a añadir una impresora para ver cual sería el proceso a seguir paso a paso.
Primero, me conecto a mi cuenta de Google en el navegador Chrome. Tras esto nos vamos a Configuración
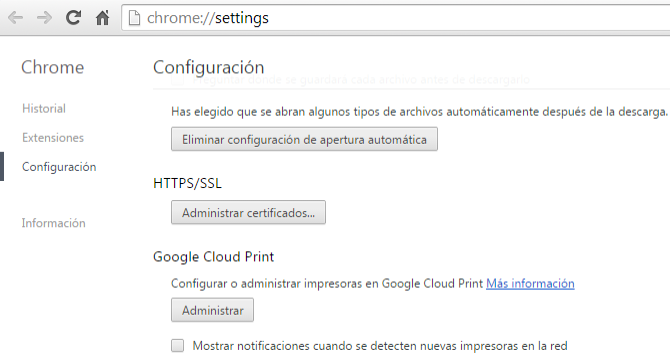
Y le damos a Administrar Google Cloud Print. Nos llevará a la siguiente página:

En mi caso voy a añadir una impresora clásica, ya que no está preparada para Cloud Printing.
Nos aparecerá otra pantalla donde nos detectará los dispositivos de impresión conectados al ordenador:

Elegimos la que queremos añadir, en mi caso la Epson ESC/P-R.

Si ahora accedemos a la página de administración de impresoras de Google Cloud Print, podemos ver todos los dispositivos disponibles:
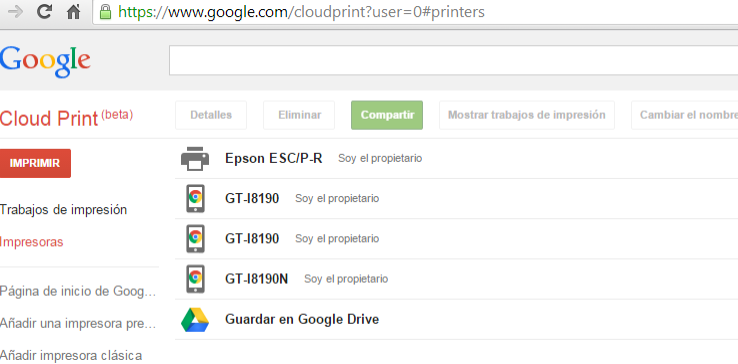
Incluso nos da la opción de subir directamente un trabajo desde el ordenador para impresión o ver la cola de trabajos de impresión.

Voy a imprimir un documento que ya tengo en mi Drive. Para ello, accedo a Drive, al documento en si y le doy a la pestaña de imprimir.

Nos saldrá la configuración de impresión. Si pulsamos sobre destino, podremos elegir la impresora que va a imprimir el documento:

Sólo tenemos que elegir la impresora de Google Cloud Print que queramos usar y listo.
Por último, mencionar otros servicios disponibles que son alternativos a Google Cloud Print, como pueden ser Apple Airprint, ThinPrint Cloud Printer o PrintNode.
El primero está pensado exclusivamente para dispositivos Apple y por desgracia parece ser que sólo funciona si el dispositivo se encuentra en la misma LAN que la impresora, por lo cual no se podría llamar del todo alternativa.
ThinPrint Cloud Printer en cambio es un servicio que funciona para todo tipo de dispositivos independientemente de la plataforma y a través de la nube.
PrintNode tiene asimismo un cliente multiplataforma, permitiendo incluso añadir Cloud Printing a nuestras aplicaciones si somos desarrolladores. Aseguran en su web, que los documentos que se mandan para imprimir por la nube no son almacenados en sus servidores, como puede pasar con Google. La única pega que tiene es que no es un servicio gratuito.
Configurar una VPN sobre SSH
Vamos a crear una VPN entre 2 redes mediante ssh.
Para ello voy a necesitar de 4 máquinas, 2 de ellas tienen habilitadas 2 interfaces de red, una que las conecta con una red LAN y la otra que les conecta con el exterior via IP pública. Las otras 2 máquinas van a ser simples clientes de las respectivas LAN, que se conectan al exterior mediante los 2 servidores LAN.
1º Servidor:


1º Cliente:

2º Servidor:

2º Cliente:

Tenemos instalado el servicio ssh en el servidor 1 y vamos a crear un túnel entre dicha máquina y el servidor 2:

Podemos observar como se han creado las nuevas interfaces en ambas máquinas:


Les asignamos IP:

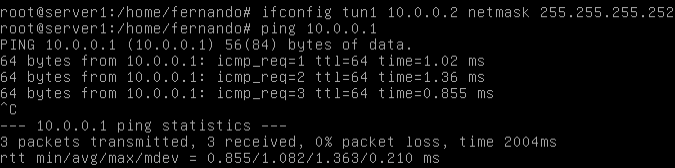
Como vemos, podemos hacer ping entre las 2 máquinas sin problemas, a través de nuestras interfaces creadas.
Lo siguiente que vamos a hacer, es enrutar las direcciones de ambas redes para que las máquinas puedan acceder no sólo entre si, sino también a los clientes de las redes LAN:


De esta forma ha quedado la tabla de enrutamiento de uno de los servidores:

Pues ya está listo. Para terminar podemos comprobar como desde una máquina de la red LAN 172.16.0.0, podemos hacer ping a otra de la red LAN 192.168.1.0
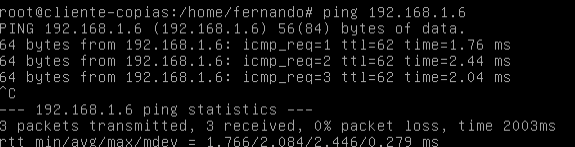
Esta es, sin embargo, una VPN temporal, ya que sólo se mantiene mientras tengamos el enlace SSH abierto. Una vez cerrado, se perderá.
Para que podamos configurar una VPN de forma permanente, necesitaremos de otro tipo de soluciones como OpenVPN.
Crear un sitio mediante IIS (Internet Information Services)
Vamos a ver el funcionamiento de IIS o Internet Information Services, el servicio de servidor web disponible para sistemas operativos Windows. Para ello voy a usar una máquina virtual con Windows 2008 server.
Tenemos que irnos al Administrador del Servidor y añadir una nueva función de servidor, la cual será la de Servidor web(IIS): Podemos ver como el propio servicio nos permite habilitar muchas funciones:
Podemos ver como el propio servicio nos permite habilitar muchas funciones:

Incluyendo distintas posibilidades de autentificación web:

Una vez instalado el servicio, accedemos a el mediante Inicio>Herramientas Administrativas>Administrador de Internet Information Services (IIS). Nos saldrá la siguiente pantalla:
Podemos ver cual es la página por defecto que tiene habilitada nuestro servidor web:

A continuación, vamos a crear un sitio para probar su funcionamiento. En ‘Sitios’, hacemos click sobre ‘Añadir nuevo sitio‘:

Podemos elegir, la carpeta donde se van a guardar los ficheros de nuestro sitio, elegir la url que va a tener, si va a ser http o https, el puerto por el que se va a acceder, etc.
Tras crearlo, lo iniciamos en la opción que aparece en la barra lateral derecha y ya tenemos nuestro sitio creado.
No nos olvidemos de introducir la dirección de nuestro sitio en el archivo hosts:

Creamos nuestra página de inicio de nuestro sitio, que se albergará en la carpeta elegida al crear el sitio: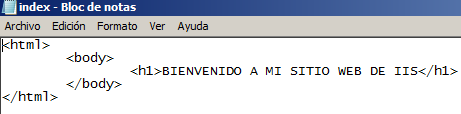
Y accedemos mediante el navegador:

Otros métodos de autentificación en Apache
Vamos a ver otros métodos de autentificación web con Apache distintos a LDAP.
AUTH_DIGEST
Primero vamos a usar Auth_Digest. Para ello habilitamos el módulo Auth_digest:
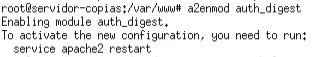
Ahora editamos el sitio que vamos a usar para la identificación, yo he usado el sitio que tengo habilitado para el CMS de MediaWiki:

Reiniciamos Apache para que ejecute los cambios y creamos el archivo digest que va a almacenar los usuarios con sus contraseñas:
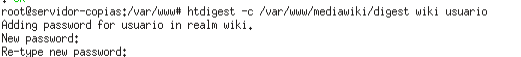
Con la opción -c, estamos especificando la creación del fichero, si vamos a introducir más usuarios después, ejecutaremos el comando sin dicha opción.
‘wiki‘ es el nombre que voy a usar para el realm o reino donde se va a encontrar ese usuario.
Si visualizamos el archivo digest, veremos el usuario creado y su contraseña cifrada:

Sólo nos queda irnos a nuestro navegador web e introducir la dirección de nuestra web que vamos a asegurar con digest. Nos saldrá un mensaje para realizar el login: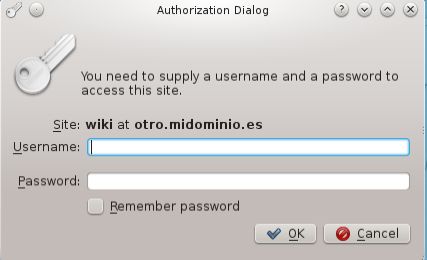
Nos autentificamos con el usuario creado en el archivo digest y accedemos a nuestro sitio:
AUTH_BASIC
Se puede usar asimismo, el tipo de autentificación Basic en vez de Digest, en el cual la transferencia de datos se produce sin cifrar, por lo cual es totalmente inseguro. Sólo habría que habilitar el módulo auth_basic en vez del módulo auth_digest y en la directiva AuthType poner Basic. El sistema de creación del archivo de almacenaje de usuarios y claves es el mismo.
MYSQL
Otra forma de autentificarnos es mediante MySQL. Nos tenemos que descargar el módulo:

Y luego lo habilitamos
Entramos en mysql:

Y ejecutamos los siguientes comandos para crear la base de datos y las tablas:


No es necesario el que el campo de la clave sea tan grande, pero si se se necesitarán, al menos, 20 caracteres si se va a usar hashing MD5.
Nos vamos al sitio, en mi caso uno que tenía preparado con un CMS de WordPress y añadimos las siguientes líneas:
Sólo nos queda reiniciar apache y entrar via navegador en nuestra página, donde nos saltará el mensaje de autentificación:

Nos autentificamos con el usuario ‘test’ y la contraseña ‘test’ como metimos en la base de datos y podremos acceder a nuestro sitio.
Se puede usar también el módulo authn_dbd para usar una base de datos relacional, sin embargo, este módulo no admite encriptación MD5 normal y es necesario la instalación del siguiente driver para DBD si se va a utilizar MySQL:

Autentificación con LDAP en Apache
Vamos a configurar Apache de forma que pida autentificación mediante LDAP a la hora
de acceder a uno de los 3 CMS que tenemos instalado en nuestro servidor, en mi caso:
Joomla
Primero debemos de tener instalado ldap y cargada una estructura de uo, grupos y usuarios,
he aprovechado una práctica de sistemas que hicimos para ello, teniendo cargados
2 usuarios: profesor y alumno.


Lo que tenemos que hacer ahora es cargar los módulos de ldap de apache, para ello:

Tras esto, toca modificar la configuración del directorio que queremos sea seguro, añadiendo
una serie de directivas:

Con AuthLDAPUrl le especificamos la url del servidor LDAP y terminamos con un ‘?
uid’ para que identifique al usuario por su uid.
AuthLDAPBindDN es para que use la cuenta de administrador de LDAP y AuthLDAPBindPassword para la contraseña de administrador.
AuthLDAPGroupAttributeIsDN está en off para que no use el cn del usuario sino el uid
a la hora de comprobar la pertenencia a un grupo.
AuthLDAPGroupAttribute es para indicar el campo que se analiza para comprobar la
pertenencia a un grupo.
Require ldap-user solo permite el acceso a los usuarios especificados.
Tras configurar el sitio, lo cargamos con a2ensite y reiniciamos Apache.
Cuando intentamos entrar a nuestra dirección: seguro.midominio.es, nos pedirá autentificarnos: Primero intentamos identificarnos con el usuario alumno, lo cual nos da error:
Primero intentamos identificarnos con el usuario alumno, lo cual nos da error:

Luego, lo hacemos con el usuario profesor:

GUÍA BÁSICA DE POSTGRESQL PARA DEBIAN Y WINDOWS
ESTRUCTURA Y FUNCIONAMIENTO
Postgresql es un sistema gestor de base de datos relacional orientado a objetos, distribuido bajo licencia BSD y de código abierto.
Utiliza un modelo cliente/servidor y usa multiprocesos en vez de multihilos para garantizar la estabilidad del sistema. Un fallo en uno de los procesos no afectará el resto y el sistema continuará funcionando.
A continuación podemos ver un esquema de la estructura básica del sistema PostgreSQL:

- Aplicación cliente: Esta es la aplicación cliente que utiliza PostgreSQL como administrador de bases de datos. La conexión puede ocurrir via TCP/IP ó sockets locales.
- Demonio postmaster: Este es el proceso principal de PostgreSQL. Es el encargado de escuchar por un puerto/socket por conexiones entrantes de clientes. Tambien es el encargado de crear los procesos hijos que se encargaran de autentificar estas peticiones, gestionar las consultas y mandar los resultados a las aplicaciones clientes
- Ficheros de configuracion: Los 3 ficheros principales de configuración utilizados por PostgreSQL, postgresql.conf, pg_hba.conf y pg_ident.conf
- Procesos hijos postgres: Procesos hijos que se encargan de autentificar a los clientes, de gestionar las consultas y mandar los resultados a las aplicaciones clientes
- PostgreSQL share buffer cache: Memoria compartida usada por POstgreSQL para almacenar datos en caché.
- Write-Ahead Log (WAL): Componente del sistema encargado de asegurar la integridad de los datos (recuperación de tipo REDO)
- Kernel disk buffer cache: Caché de disco del sistema operativo
- Disco: Disco físico donde se almacenan los datos y toda la información necesaria para que PostgreSQL funcione
Algunas de sus principales características son:
Alta concurrencia
Permite que mientras un proceso escribe en una tabla, otros accedn a la misma tabla sin necesidad de bloqueos.
Amplia variedad de tipos nativos
Soportando:
- Números de precisión arbitraria.
- Texto de largo ilimitado.
- Figuras geométricas
- Direcciones IP o MAC.
- Arrays
Otras Características:
- Claves ajenas.
- Triggers o disparadores.
- Vistas.
- Integridad transaccional.
- Herencia de tablas.
- Tipos de datos y operaciones geométricas.
- Soporte para transacciones distribuidas.
Funciones en lenguajes:
- PL/PgSQL (Lenguaje propio)
- C/C++
- Java PL/Java web
- PL/Perl
- plPHP
- PL/Python
- PL/Ruby
- PL/sh
- etc.

INSTALACIÓN EN SERVIDOR LINUX
Descargamos el paquete a instalar:
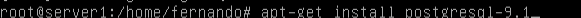
Ahora hay que cambiarle la contraseña al usuario ‘postgres’ que se crea al realizar la instalación

Asimismo, hay que hacerlo mediante la consola de administración de postgresql:

A continuación vamos a configurar el archivo de configuración postgresql.conf para que admita conexiones desde fuera (he puesto ‘*’, ya que estoy manejando máquinas virtuales, en realidad ‘*’ resulta en un fallo de seguridad al permitir todo tipo de conexiones entrantes):

Y luego el archivo pg_hba.conf para especificar si queremos la base de datos, usuario, dirección o direcciones que se va a permitir que se conecten y el método de autenticación:

En mi caso, he puesto la dirección de otro cliente de la red interna, sólo para comprobar el funcionamiento de la conexión remota.
Ahora vamos a crear un usuario para que se pueda conectar a la base de datos:
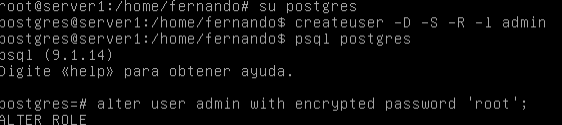
Con las opciones dadas (-D -S -R -l), al usuario no se le permite crear bases de datos, ni ser superusuario, ni crear roles, pero se le permite iniciar sesión. Luego, se le ha asignado una contraseña.
Se puede comprobar su creación de la siguiente manera:

Tras crear el usuario, lo próximo va a ser crear la base de datos:

Con las opciones, le hemos asignado una plantilla, hemos asignado un usuario propietario de la misma y especificado el esquema de codificación, así como, el nombre de la base de datos.
Tras esto habrá que darle permisos al usuario creado para esta base de datos:
Asimismo, podemos ver como se ha creado la base de datos:

El último comando nos permite corroborar la creación de la base de datos, igual que cuando lo hicimos con el usuario.
Una vez hecho esto, reiniciamos el servicio y desde un cliente (192.168.0.2 en mi caso) probamos a conectarnos a la base de datos:
Con la opción -h especificamos el host al que nos conectamos, con -d el nombre de la base de datos y con -U el usuario con el que nos vamos a conectar.
Como vemos, se nos conecta, por lo cual postgresql ya está instalado y configurado en nuestro Debian.
INSTALACIÓN EN WINDOWS
Para realizar la instalación de Postgresql en Windows nos vamos a bajar la plataforma de desarrollo y administración pgAdmin. Nos vamos a su pagina oficial y nos descargamos la versión más actual:
Una vez instalada (pasos sencillos, dejando las opciones por defecto) nos aparecerá la siguiente interfaz:

Nos conectamos al servidor que hay y nos pedirá contraseña, la cual hemos introducido durante la instalación:

Primero vamos a crear un rol nuevo, para ello nos vamos a la sección login roles y con botón derecho añadimos un nuevo rol:
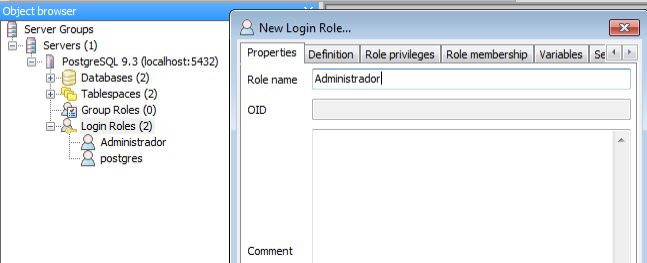
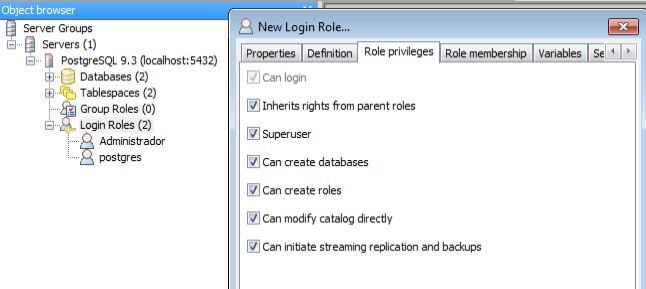
Nos vamos a la pestaña de privilegios y le marcamos todos los permisos ya que es el que va a crear las bases de datos y demás, si sólo queremos un usuario que se pueda loguear como en la instalación de Linux, sólo dejamos la opción de login marcada:
Asimismo, creamos una base de datos:

CLIENTE WEB
Antes de ponernos a implementar nuestra base de datos, vamos a ver un cliente web que podemos usar para Postgresql llamado PhpPgAdmin, para ello vamos a su página oficial y lo descargamos:
Como podemos observar, da la opción de bajarnos los paquetes para entorno Linux y Windows. Para ver como funciona, yo he descargado la versión Windows.
Una vez descargado el paquete, lo descomprimimos en la carpeta htdocs de nuestro servicio Xampp. Si en vez de Xampp, tenemos Wampp, lo tendremos que descomprimir en su carpeta correspondiente.
Sin embargo, hay que hacer una cosa más antes de poder acceder y es enlazar php con postgresql, para ello nos debemos ir al archivo de configuración php.ini, buscar la linea comentada:
;extension=php_pgsql.dll #Si estamos en Windows
;extension=pgsql.so #En Linux
y descomentarla. Una vez hecho esto, reiniciamos el servicio Apache y ya podemos acceder a través de nuestro navegador poniendo la dirección http://localhost/phpPgAdmin-5.1



DESARROLLO DE LA BBDD
Ahora, vamos a implementar una base de datos sobre un caso específico y que nos servirá a modo de ejemplo para ver el funcionamiento de Postgresql.
Primero vamos a analizar en que consiste el escenario y que es lo queremos hacer exactamente en nuestra base de datos: «Una gestión académica de los alumnos del departamento de informática del IES Gran Capitán.»
Por lo tanto vamos a necesitar tanto información sobre los alumnos, así como de los profesores y de las asignaturas que imparten.
También habrá que distinguir en que cursos se matriculan los alumnos, de que asignaturas y si se trata de los grupos de mañana o tarde en caso de que así esté implementado en el ciclo.
Asimismo, se querrá saber las notas de cada alumno dependiendo de cada asignatura y de cada trimestre, los tutores de cada curso, así como los delegados de cada curso. Esto nos deja un esquema como el siguiente: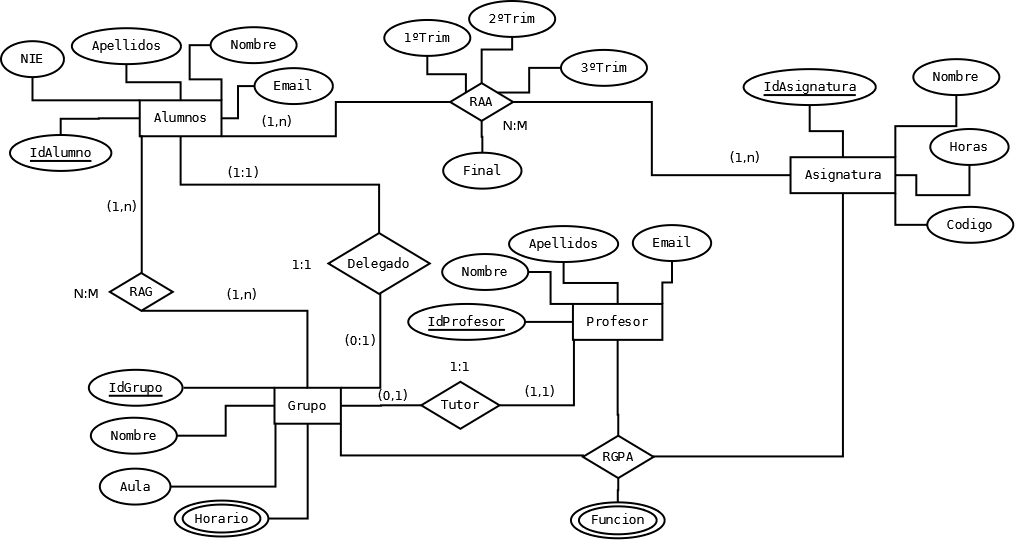
El siguiente paso sería pasar el modelo ER al modelo relacional, que quedaría de la siguiente forma tras haber normalizado:
Alumnos( IdAlumno/PK, Nombre, Apellido, NIE, Email)
Grupo( IdGrupo/PK, Nombre, Aula, Horario, idDelegado/FK, idTutor/FK)
RAG(( idAlumno/FK, idGrupo/FK)/PK)
Profesor( IdProfesor/PK, Nombre, Apellidos, Email)
Asignatura( IdAsignatura/PK, Nombre, Código, Horas)
RAA(( IdAlumno/FK, IdAsignatura/FK)/PK, 1ºTrim, 2ºTrim, 3ºTrim, Final)
RGPA(( IdGrupo/FK, IdAsignatura/FK, IdProfesor/FK)/PK, Función)
Vamos a pasar ahora a la implementación del diseño físico:
IMPLEMENTACIÓN EN WINDOWS
Procedemos a crear las distintas tablas de las que va a contar nuestro esquema:
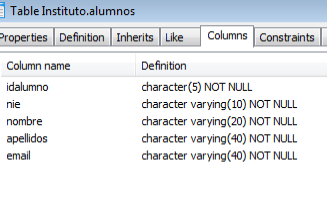
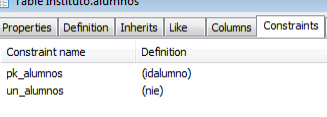
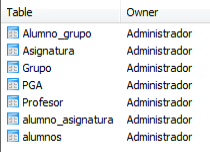
Para la carga de datos podemos entrar los datos manualmente o cargarlos desde archivos de texto plano, csv o binarios en ‘Herramientas>Importar‘:
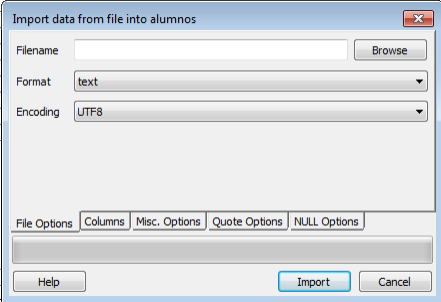
Una vez introducidos todos los datos en sus correspondientes tablas podemos llevar a cabo las consultas que queramos realizar mediante la herramienta que nos proporciona postgresql, tanto mediante comandos sql como de forma gráfica:
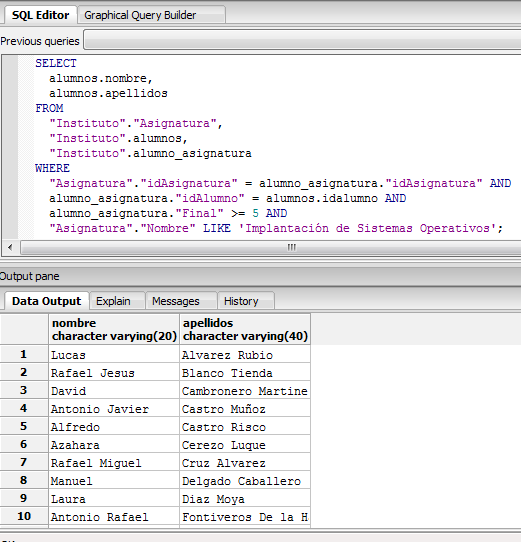
Vamos a realizar algunas consultas de ejemplo para ver si funciona nuestra implementación:
- Quiero que me muestre todos aquellos alumnos que a final de curso han aprobado la asignatura ‘Implantación de Sistemas Operativos’.
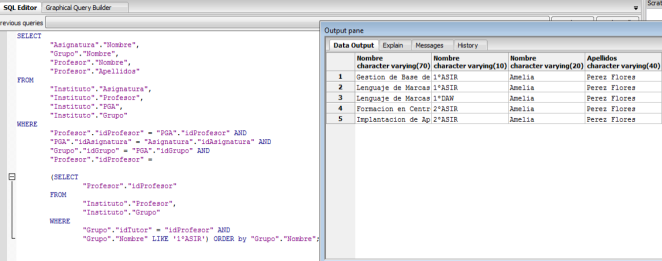
- Quiero que me muestre el tutor de 1ºASIR y las asignaturas que da en los distintos grupos y los grupos en el que las da, ordenado por el grupo:
- Quiero saber cuantos alumnos tiene cada grupo:
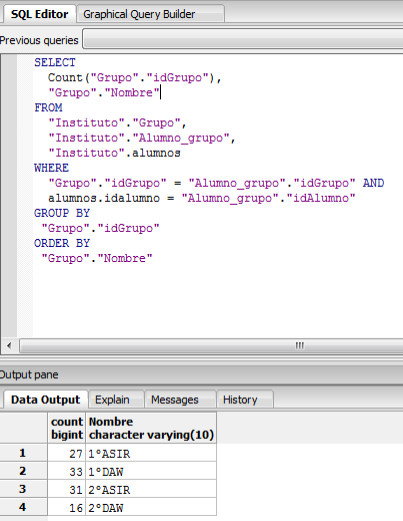

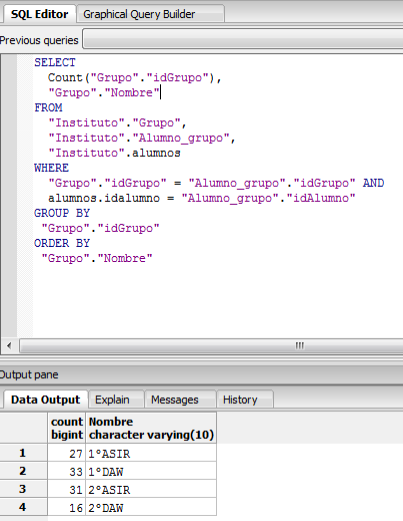
Antes de pasar a la implementación en Linux, vamos a hacer un backup de nuestra base de datos para cargarla directamente desde el servidor Linux y no tener que volver a hacerlo todo de nuevo.
Para eso nos vamos a ‘Herramientas>backup‘ y lo vamos a guardar como archivo de texto plano:
SERVIDOR DEBIAN
Tenemos que tener cuidado con que el usuario que va a administrar la base de datos y el nombre de la misma son iguales a los del archivo creado en el servidor Windows, si no, va a dar problemas.
Una vez en el servidor escribimos la siguiente linea: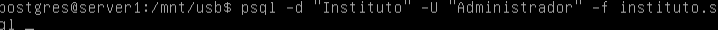
Especificando la base de datos, el usuario propietario y el archivo del que vamos a importar la información de la base de datos.
Al llevar a cabo el comando de arriba, se nos van a ejecutar todos los comandos de CREATE, ALTER e INSERT necesarios.
Para poder comprobar que efectivamente se nos han cargado las tablas, iniciamos sesión en la base de datos y ejecutamos el siguiente comando:
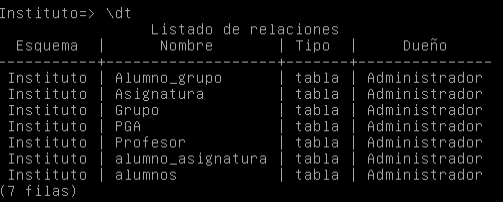 Si no tenemos la suerte de tener la información de la bbdd disponible para cargarla directamente, ya que, no la hemos creado con anterioridad, tendremos que crear las tablas e insertar los datos mediante comandos SQL, ya sea manualmente o mediante scripts.
Si no tenemos la suerte de tener la información de la bbdd disponible para cargarla directamente, ya que, no la hemos creado con anterioridad, tendremos que crear las tablas e insertar los datos mediante comandos SQL, ya sea manualmente o mediante scripts.
Tras esto, podemos realizar algunas consultas para comprobar que funciona correctamente:
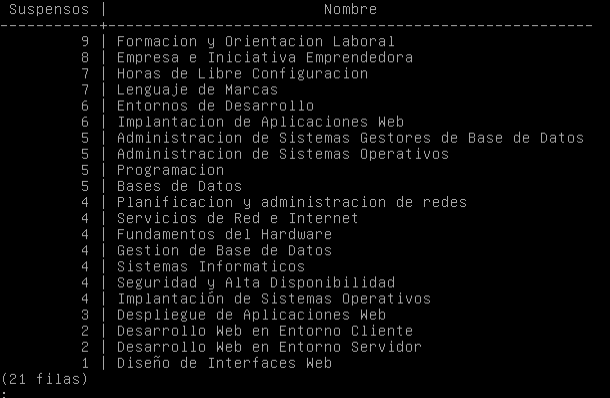
- Quiero obtener el número de suspensos en la evaluación Final por asignatura ordenados de mayor a menor número:

- Se ha cambiado de delegado en el curso de 2ºDAW:
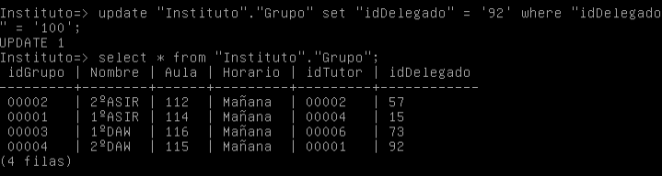



Como vemos nuestra base de datos funciona como queríamos.
Diferencias entre Inittab y Upstart
Inittab es el archivo de configuración que usa el demonio init. Usado originalmente en distribuciones System V como Red Hat y Debian y distribuciones BSD como Slackware.
Suele encontrarse en /etc/ y describe los procesos que se van a ejecutar al iniciar el sistema.
Los procesos se encuentran separados en un total de 11 runlevels o niveles de ejecución. Normalmente, el nivel 0 se usa para detener el sistema, el 6 para reiniciar el sistema y el nivel 1 para usar el sistema en modo monousuario.
En Debian, por ejemplo, se usa por defecto el nivel 2 de ejecución:
Si queremos saber en que nivel de ejecución se encuentra nuestro sistema, siempre podemos ejecutar el comando: runlevel
En el archivo inittab, que es llamado por init tras la carga del kernel, se definen entradas, para realizar acciones en los niveles deseados, de la siguiente forma:
id. nivel_de_ejecución: acción: proceso
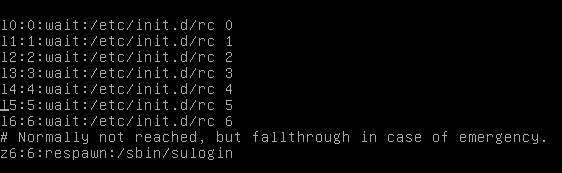
Estos procesos se encuentran dentro de los ficheros /etc/rcn.d (donde n es el numero asociado al runlevel).
Si vemos dentro de estos ficheros, lo que vemos dentro de ellos son scripts o enlaces a los scripts que controlan esos servicios:

Como podemos observar cada enlace tiene un nombre relacionado con el servicio, una S o K que indica si se va a iniciar (S) o matar (K) el servicio, y un número que representa el orden en que se van a ejecutar los servicios.
Hay una serie de comando útiles para manejar los niveles de ejecución:
- Con /etc/init.d/nombre_demonio start/restart/stop, podemos iniciar, reiniciar o para respectivamente un servicio.
- Telinit nos permite cambiar de nivel de ejecución si indicamos el número. Por ejemplo: si hacemos un telnit 1 pasamos a modo monousuario
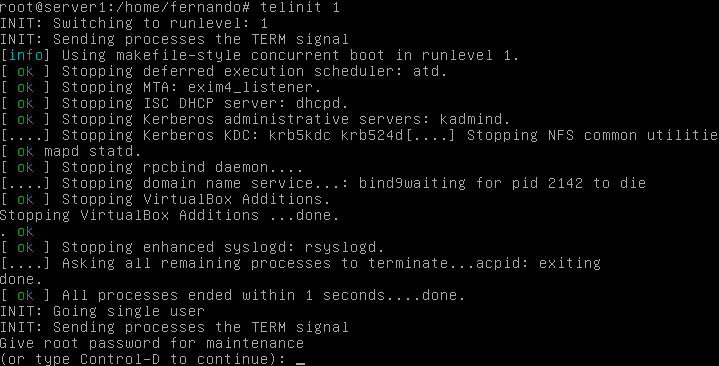
- Shutdown permite parar con opción ‘-h’ o reiniciar con la opción ‘-r’. También podemos usar los comandos halt y reboot.

- Wall permite crear mensajes de advertencia a los usuarios de sistema.
- Pidof permite averiguar el PID asociado a un proceso. También podemos usar el comando ps. Muy útil si queremos usar kill en algún proceso.
Upstart es un reemplazo basado en eventos para el demonio init y que fue adoptada por distribuciones Linux como Ubuntu 9.10 (de forma nativa) o Chrome OS.
Que sea basado en eventos significa que los procesos o jobs, se iniciarán y pararán automáticamente con respecto a cambios que ocurran en el sistema. Esto puede suponer una ventaja desde el punto de vista de que permite interactuar automáticamente con el sistema, los servicios y el demonio init.
Para poder ejecutar procesos en inittab usabamos /etc/init.d, sin embargo Upstart tiene su propio método, el cual suele tener una sintaxis parecida a esta:
Acción nombre_proceso
Como por ejemplo: start portmap.
También podemos usar el comando service. Service nos va a permitir tanto interactuar con scripts en inittab como en Upstart
Uno de los comandos básicos más útiles en Upstart es initctl, una herramienta de control de los demonios de los procesos. Con él podemos iniciar, reiniciar, recargar, parar, etc los distintos procesos del sistema. Por ejemplo:

También podemos usar un initctl list para que nos liste el estado de todos los servicios del sistema:
Por último, al menos en Ubuntu y Debian, al instalar un nuevo servicio, se habilita por defecto dentro del proceso de arranque. Sin embargo, si queremos iniciar nuevos servicios en el proceso de arranque, o cambiar los niveles de ejecución en los que se inician o paran podemos usar el comando update-rc.d.
Por ejemplo:

Esto creará enlaces para arrancar el servicio samba en los niveles de ejecución 2345 y pararlos en los niveles de ejecución 016. Además especificamos la prioridad que tendrá (20). Como estos suelen ser los valores por defecto, también podíamos haber puesto:
update-rc.d samba defaults
En cambio, si lo que queremos es eliminar un servicio del proceso de arranque podemos ejecutar el siguiente comando:

Estos comando funciona tanto en Upstart como en inittab:

Fuentes:
http://linux.die.net/man/8/init
